Auditory perception is an essential part of a robotic system in Human-Robot Interaction (HRI), and creating an artificial auditory perception system that is on par with human has been a long-standing goal for researchers. In fact, this is a challenging research topic, because in typical HRI scenarios the audio signal is often corrupted by the robot ego noise, other background noise and overlapping voices. The traditional approaches based on signal processing seek analytical solutions according to the physical law of sound propagation as well as assumptions about the signal, noise and environments. However, such approaches either assume over-simplified conditions, or create sophisticated models that do not generalize well in real situations.
This thesis introduces an alternative methodology to auditory perception in robotics by using deep learning techniques. It includes a group of novel deep learning-based approaches addressing sound source localization, speech/non-speech classification, and speaker re-identification. The deep learning-based approaches rely on neural network models that learn directly from the data without making many assumptions. They are shown by experiments with real robots to outperform the traditional methods in complex environments, where there are multiple speakers, interfering noises and no a priori knowledge about the number of sources.
In addition, this thesis addresses the issue of high cost of data collection which arises with learning-based approaches. Domain adaptation and data augmentation methods are proposed to exploit simulated data and weakly-labeled real data, so that the effort for data collection is minimized. Overall, this thesis suggests a practical and robust solution for auditory perception in robotics in the wild.
Weipeng He
PhD dissertation, EPFL,
2021
Despite the recent success of deep neural network-based approaches in sound source localization, these approaches suffer the limitations that the required annotation process is costly, and the mismatch between the training and test conditions undermines the performance. This paper addresses the question of how models trained with simulation can be exploited for multiple sound source localization in real scenarios by domain adaptation. In particular, two domain adaptation methods are investigated: weak supervision and domain-adversarial training. Our experiments show that the weak supervision with the knowledge of the number of sources can significantly improve the performance of an unadapted model. However, the domain-adversarial training does not yield significant improvement for this particular problem.
Weipeng He, Petr Motlicek, Jean-Marc Odobez
In ICASSP,
2019
We propose a novel multi-task neural network-based approach for joint sound source localization and speech/non-speech classification in noisy environments. The network takes raw short time Fourier transform as input and outputs the likelihood values for the two tasks, which are used for the simultaneous detection, localization and classification of an unknown number of overlapping sound sources, Tested with real recorded data, our method achieves significantly better performance in terms of speech/non-speech classification and localization of speech sources, compared to method that performs localization and classification separately. In addition, we demonstrate that incorporating the temporal context can further improve the performance.
Weipeng He, Petr Motlicek, Jean-Marc Odobez
In INTERSPEECH,
2018
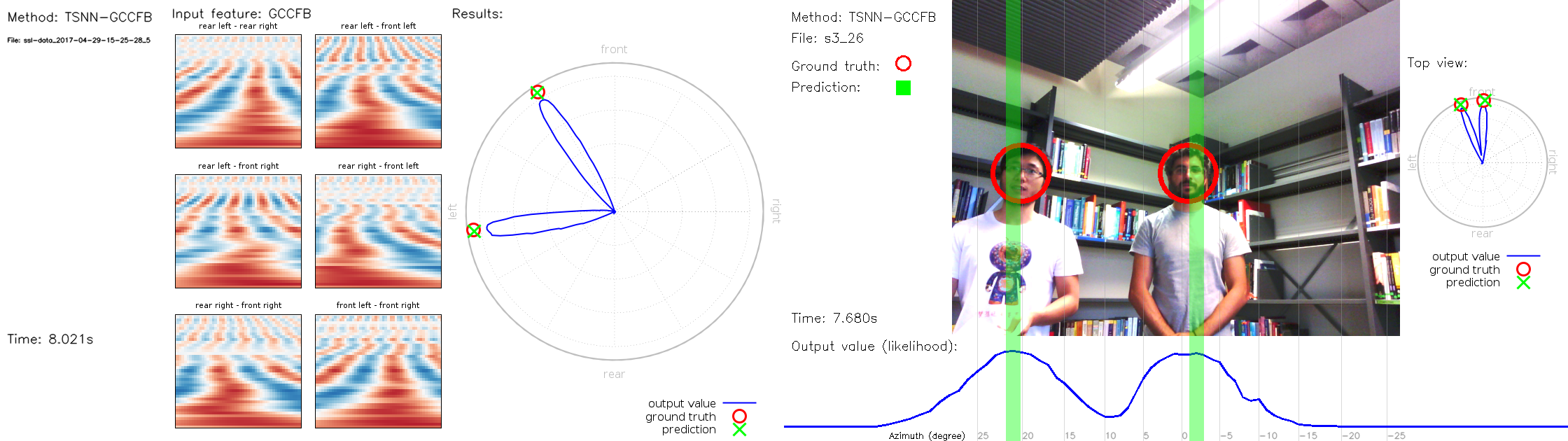
We propose using neural networks for simultaneous detection and localization of multiple sound sources in human-robot interaction. In contrast to conventional signal processing techniques, neural network-based sound source localization methods require fewer strong assumptions about the environment. Previous neural network-based methods have been focusing on localizing a single sound source, which do not extend to multiple sources in terms of detection and localization. In this paper, we thus propose a likelihood-based encoding of the network output, which naturally allows the detection of an arbitrary number of sources. In addition, we investigate the use of sub-band cross-correlation information as features for better localization in sound mixtures, as well as three different network architectures based on different motivations. Experiments on real data recorded from a robot show that our proposed methods significantly outperform the popular spatial spectrum-based approaches.
Weipeng He, Petr Motlicek, Jean-Marc Odobez
In ICRA,
2018