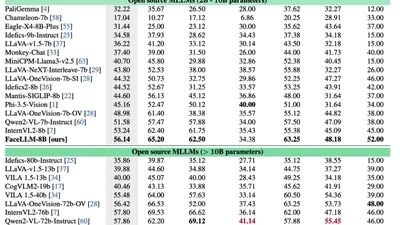
FaceLLM: A Multimodal Large Language Model for Face Understanding
Multimodal large language models (MLLMs) have shown remarkable performance in vision-language tasks. However, existing MLLMs are primarily trained on generic datasets, limiting …
Multimodal large language models (MLLMs) have shown remarkable performance in vision-language tasks. However, existing MLLMs are primarily trained on generic datasets, limiting …