


SummaryHATDOC is a dataset which contains human attention scores to sentences when attributing specific categories (aspect ratings) to documents (audiobook reviews). The annotations were obtained using at least 4 qualified judges per sentence using a crowdsourcing platform, namely 100 audiobook reviews with 1,662 sentences and three aspects: story, performance, and overall quality. In addition, we provide a dataset of 50K audiobook reviews with document-level aspect ratings that can be used for weakly supervised training. The data are suitable for intrinsic evaluation of explicit document modeling models with attention mechanisms in the task of aspect sentiment analysis and summarization of reviews. |

|
Getting started
- Explore the dataset of audiobook reviews annotated with sentence-level human attention scores.
- Download the training set which contains audiobook reviews accompanied by aspect ratings for weakly supervised training.
- Download the test set of audiobook reviews annotated with sentence-level human attention scores.
- Evaluate your system on two tasks using our evaluation script under HATDOC-test/aggregated_evaluation/ folder:
- Multi-aspect review summarization
$ python eval.py wmil-sgd_predictions/attention/ --sum
- Multi-aspect review rating prediction
$ python eval.py wmil-sgd_predictions/ratings/ --rat
- The code of our system is available on Github.
System: weighted multiple-instance regression
Weighted MIR jointly learns to predict target labels and to focus on relevant or salient regions of the input (analogous to one-layer attention neural networks). The current implementation which is available on Github (wmil-sgd) assumes that a document Bi is represented by a set of fixed sentence vectors, however the sentence vectors could also be modeled by any type of neural network (e.g. LSTM). The attention is modeled by a normalized exponential function, namely softmax and a linear activation between a contextual vector O and the sentence vectors Bi (document matrix):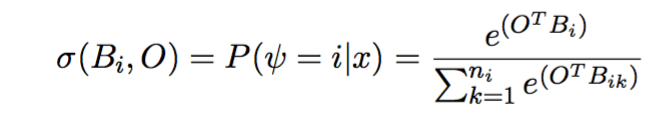
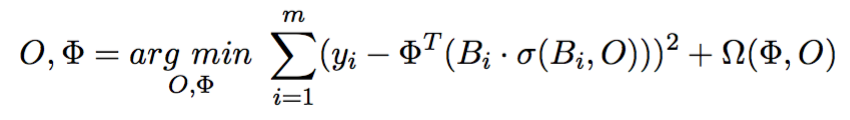
Highlights: human versus machine attention
We evaluated the performance of a one-layer attention document model using weighted MIR trained on the 50k dataset and tested on the HATDOC test set. The figure below displays the accuracy of the evaluated system (MIR) on predicting the explanatory value of sentences with respect to review-level ratings of the three aspects, for subsets of increasing crowd confidence values. The expected accuracy of a supervised system trained on the attention labels with 10-fold cross-validation, namely Logistic Regression, is noted as LogReg. Random accuracy is 1 out of 5, i.e. 20%.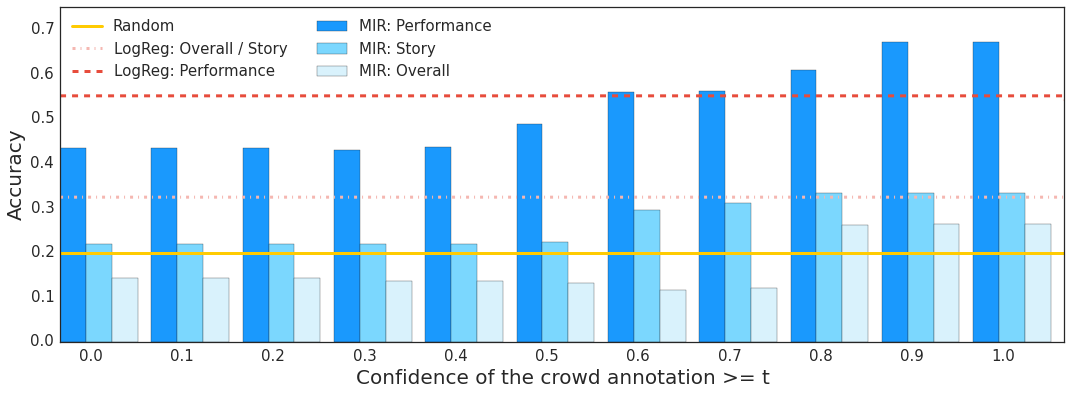
Download a pre-trained document attention model
The Weighted MIR model described above was trained on the above HATDOC training set (50k) using bag-of-words (38k vocabulary) features and a weakly supervised objective. The obtained document attention model is available for download below. The model has implemented functions for predicting the aspect ratings of unseen documents as well as for estimating the saliency or relevance scores per sentence (attention) with respect to the predicted document-level aspect ratings.References
- Nikolaos Pappas, Andrei Popescu-Belis, Human versus Machine Attention in Document Classification: A Dataset with Crowdsourced Annotations, SocialNLP @ EMNLP, Austin, Texas, 2016
- Nikolaos Pappas, Andrei Popescu-Belis, Explaining the Stars: Weighted Multiple-Instance Learning for Aspect-Based Sentiment Analysis, EMNLP, Doha, Qatar, 2014
Acknowledgments
We are grateful for funding to the European Union's Horizon 2020 program through the SUMMA project (Research and Innovation Action, grant agreement n. 688139): Scalable Understanding of Multilingual Media, see http://www.summa-project.eu/.Citing dataset
@inproceedings{hatdoc,
author = {Pappas, Nikolaos and Popescu-Belis, Andrei},
title = {Human versus Machine Attention on Document Classification: A Dataset with Crowdsourced Annotations},
booktitle = {Proceedings of the EMNLP 2016 SocialNLP Workshop},
series = {EMNLP'16},
year = {2016},
address = {Austin, USA}
}