Algorithms¶
Algorithms are user-defined piece of software that run within the blocks of a toolchain. An algorithm can read data on the input(s) of the block and write processed data on its output(s). They are, hence, key components for scientific experiments, since they formally describe how to transform raw data into higher level concept such as classes.
An algorithm lies at the core of each processing block and may be subject to parametrization. Inputs and outputs of an algorithm have well-defined data formats. The format of the data on each input and output of the block is defined at a higher-level in the platform. It is expected that the implementation of the algorithm respects whatever was declared on the platform.
By default, the algorithm is data-driven; algorithm is typically provided one data sample at a time and must immediately produce some output data. Furthermore, the way the algorithm handle the data is highly configurable and covers a huge range of possible scenarios.
Fig. 1 displays the relationship between a processing block and its algorithm.
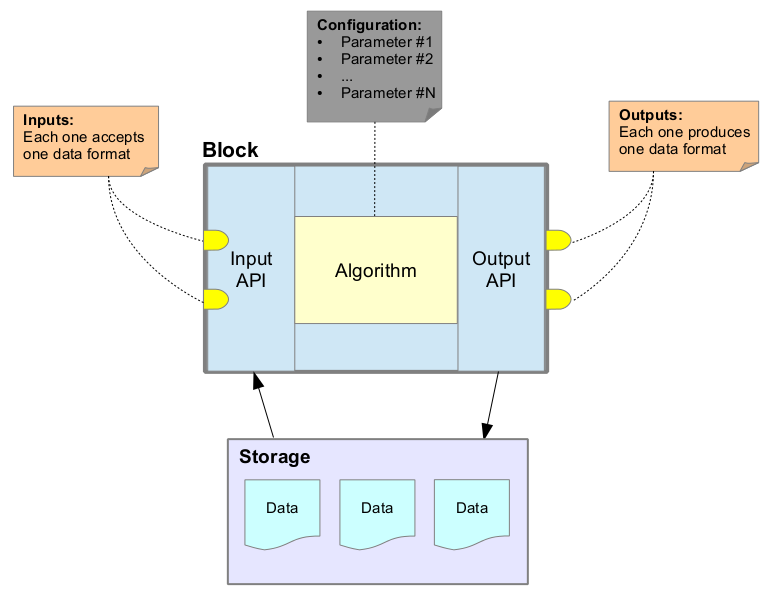
Fig. 1 Relationship between a processing block and its algorithm
This section contains information on the definition of algorithm and its programmatic use on Python-based language bindings.
Definition¶
An algorithm is defined by two distinct components:
- a JSON object with several fields, specifying the inputs, the outputs, the parameters and additional information such as the language in which it is implemented.
- source code (and/or [later] binary code) describing how to transform the input data.
JSON Declaration¶
A JSON declaration of an algorithm consists of several fields. For example, the following declaration is the one of an algorithm implementing probabilistic component analysis (PCA):
{
"language": "python",
"splittable": false,
"groups": [
{
"inputs": {
"image": {
"type": "system/array_2d_uint8/1"
}
},
"outputs": {
"subspace": {
"type": "tutorial/linear_machine/1"
}
}
}
],
"parameters": {
"number-of-components": {
"default": 5,
"type": "uint32"
}
},
"description": "Principal Component Analysis (PCA)"
}
The field language specifies the language in which the algorithm is implemented. The field splittable indicates, whether the algorithm can be parallelized into chunks or not. The field parameters lists the parameters of the algorithm, describing both default values and their types. The field groups gives information about the inputs and outputs of the algorithm. They are provided into a list of dictionary, each element in this list being associated to a database channel. The group, which contains outputs, is the synchronization channel. By default, a loop is automatically performs by the platform on the synchronization channel, and user-code must not loop on this group. In contrast, it is the responsability of the user to load data from the other groups. This is described in more details in the following subsections. Finally, the field description is optional and gives a short description of the algorithm.
The web client of the BEAT platform provides a graphical editor for algorithm, which simplifies its JSON declaration definition.
Analyzer¶
At the end of the processing workflow of an experiment, there is a special kind of algorithm, which does not yield any output, but in contrast so called results. These algorithms are called analyzers.
Results of an experiment are reported back to the user. Since the platform is concerned about data privacy, only a limited number of data formats can be employed as results in an analyzer, such as boolean, integers, floating point values, strings (of limited size), as well as plots (such as scatter or bar plots).
For example, the following declaration is the one of a simple analyzer, which generates an ROC curve as well as few other metrics.
{
"language": "python",
"groups": [
{
"inputs": {
"scores": {
"type": "tutorial/probe_scores/1"
}
}
}
],
"results": {
"far": {
"type": "float32",
"display": true
},
"roc": {
"type": "plot/scatter/1",
"display": false
},
"number_of_positives": {
"type": "int32",
"display": false
},
"frr": {
"type": "float32",
"display": true
},
"eer": {
"type": "float32",
"display": true
},
"threshold": {
"type": "float32",
"display": false
},
"number_of_negatives": {
"type": "int32",
"display": false
}
}
}
Source Code¶
The BEAT platform has been designed to support algorithms written in different programming languages. However, for each language, a corresponding back-end needs to be implemented, which is in charge of connecting the inputs and outputs to the algorithm and running its code as expected. In this section, we describe the implementation of algorithms in the Python programming language.
To implement a new algorithm, one must write a class following a few conventions. In the following, examples of such classes are provided.
Examples¶
Simple algorithm (no parametrization)¶
At the very minimum, an algorithm class must look like this:
class Algorithm:
def process(self, inputs, outputs):
# Read data from inputs, compute something, and write the result
# of the computation on outputs
...
return True
The class must be called Algorithm and must have a method called
process(), that takes as parameters a list of inputs (see section
Input list) and a list of outputs (see
section Output list). This method must
return True if everything went correctly, and False if an error
occurred.
The platform will call this method once per block of data available on the synchronized inputs of the block.
Parametrizable algorithm¶
To implement a parametrizable algorithm, two things must be added to the class:
(1) a field in the JSON declaration of the algorithm containing their default
values as well as the type of the parameters, and (2) a method called
setup(), that takes one argument, a map containing the parameters of the
algorithm.
{
...
"parameters": {
"threshold": {
"default": 0.5,
"type": "float32"
}
},
...
}
class Algorithm:
def setup(self, parameters):
# Retrieve the value of the parameters
self.threshold = parameters['threshold']
return True
def process(self, inputs, outputs):
# Read data from inputs, compute something, and write the result
# of the computation on outputs
...
return True
When retrieving the value of the parameters, one must not assume that a value
was provided for each parameter. This is why we may use a try: … except: …
construct in the setup() method.
Handling input data¶
Input list¶
An algorithm is given access to the list of the inputs of the processing block. This list can be used to access each input individually, either by their name (see section Input naming), their index or by iterating over the list:
# 'inputs' is the list of inputs of the processing block
print(inputs['labels'].data_format)
for index in range(0, inputs.length):
print(inputs[index].data_format)
for input in inputs:
print(input.data_format)
for input in inputs[0:2]:
print(input.data_format)
Additionally, the following method is useable on a list of inputs:
-
hasMoreData()¶ Indicates if there is (at least) another block of data to process on some of the inputs
Input¶
Each input provides the following informations:
-
name¶ (string) Name of the input
-
data_format¶ (string) Data format accepted by the input
-
data_index¶ (integer) Index of the last block of data received on the input (See section Inputs synchronization)
-
data¶ (object) The last block of data received on the input
The structure of the data object is dependent of the data format assigned to
the input. Note that data can be None.
Input naming¶
Each algorithm assign a name of its choice to each input (and output, see section Output naming). This mechanism ensures that algorithms are easily shareable between users.
For instance, in Fig. 2, two different users (Joe and Bill) are using two different toolchains. Both toolchains have one block with two entries and one output, with a similar set of data formats (image/rgb and label on the inputs, array/float on the output), although not in the same order. The two blocks use different algorithms, which both refers to their inputs and outputs using names of their choice
Nevertheless, Joe can choose to use Bill’s algorithm instead of his own one. When the algorithm to use is changed on the web interface, the platform will attempt to match each input with the names (and types) declared by the algorithm. In case of ambiguity, the user will be asked to manually resolve it.
In other words: the way the block is connected in the toolchain doesn’t force a naming scheme or a specific order of inputs to the algorithms used in that block. As long as the set of data types (on the inputs and outputs) is compatible for both the block and the algorithm, the algorithm can be used in the block.

Fig. 2 Different toolchains, but interchangeable algorithms
The name of the inputs are assigned in the JSON declaration of the algorithm, such as:
{
...
"groups": [
{
"inputs": {
"name1": {
"type": "data_format_1"
},
"name2": {
"type": "data_format_2"
}
}
}
],
...
}
Inputs synchronization¶
The data available on the different inputs from the synchronized channels are (of course) synchronized. Let’s consider the example toolchain on Fig. 3, where:
- The image database provides two kind of data: some images and their associated labels
- The block A receives both data via its inputs
- The block B only receives the labels
- Both algorithms are data-driven
The system will ask the block A to process 6 images, one by one. On the
second input, the algorithm will find the correct label for the current image.
The block B will only be asked to process 2 labels.
The algorithm can retrieve the index of the current block of data of each of
its input by looking at their data_index attribute. For simplicity, the
list of inputs has two attributes (current_data_index and
current_end_data_index) that indicates the data indexes currently used by
the synchronization mechanism of the platform.
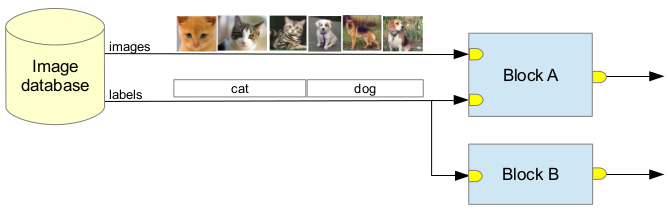
Fig. 3 Synchronization example
Additional input methods for unsynchronized channels¶
Unsynchronized input channels of algorithms can be accessed at will, and algorithms can use it any way they want. To be able to perform their job, they have access to additional methods.
The following method is useable on a list of inputs:
-
next()¶ Retrieve the next block of data on all the inputs in a synchronized manner
Let’s come back at the example toolchain on Fig. 3, and assume that block A uses an autonomous algorithm. To iterate over all the data on its inputs, the algorithm would do:
class Algorithm:
def process(self, inputs, outputs):
# Iterate over all the unsynchronized data
while inputs.hasMoreData():
inputs.next()
# Do something with inputs['images'].data and inputs['labels'].data
...
# At this point, there is no more data available on inputs['images'] and
# inputs['labels']
return True
The following methods are useable on an input, in cases where the algorithm
doesn’t care about the synchronization of some of its inputs:
-
hasMoreData() Indicates if there is (at least) another block of data available on the input
-
next() Retrieve the next block of data
Warning
Once this method has been called by an algorithm, the input is no more automatically synchronized with the other inputs of the block.
In the following example, the algorithm desynchronizes one of its inputs but keeps the others synchronized and iterate over all their data:
{
...
"groups": [
{
"inputs": {
"images": {
"type": "image/rgb"
},
"labels": {
"type": "label"
},
"desynchronized": {
"type": "number"
}
}
}
],
...
}
class Algorithm:
def process(self, inputs, outputs):
# Desynchronize the third input. From now on, inputs['desynchronized'].data
# and inputs['desynchronized'].data_index won't change
inputs['desynchronized'].next()
# Iterate over all the data on the inputs still synchronized
while inputs.hasMoreData():
inputs.next()
# Do something with inputs['images'].data and inputs['labels'].data
...
# At this point, there is no more data available on inputs['images'] and
# inputs['labels'], but there might be more on inputs['desynchronized']
return True
Feedback inputs¶
The Fig. 4 shows a toolchain containing a feedback loop. A special kind of input is needed in this scenario: a feedback input, that isn’t synchronized with the other inputs, and can be freely used by the algorithm.
Those feedback inputs aren’t yet implemented in the prototype of the platform. This will be addressed in a later version.
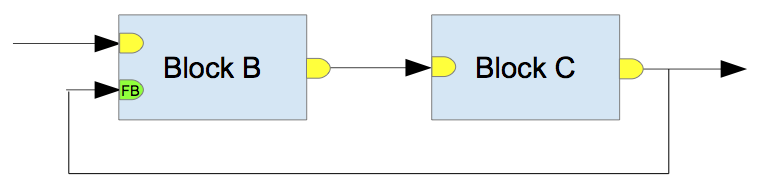
Fig. 4 Feedback loop
Handling output data¶
Output list¶
An algorithm is given access to the list of the outputs of the processing block. This list can be used to access each output individually, either by their name (see section Output naming), their index or by iterating over the list:
# 'outputs' is the list of outputs of the processing block
print outputs['features'].data_format
for index in range(0, outputs.length):
outputs[index].write(...)
for output in outputs:
output.write(...)
for output in outputs[0:2]:
output.write(...)
Output¶
Each output provides the following informations:
-
name (string) Name of the output
-
data_format (string) Format of the data written on the output
And the following methods:
-
createData()¶ Retrieve an initialized block of data corresponding to the data format of the output
-
write(data, end_data_index=None)¶ Write a block of data on the output
We’ll look at the usage of those methods through some examples in the following sections.
Output naming¶
Like for its inputs, each algorithm assign a name of its choice to each output (see section Input naming for more details) by including them in the JSON declaration of the algorithm.
{
...
"groups": [
{
"inputs": {
...
},
"outputs": {
"name1": {
"type": "data_format1"
},
"name2": {
"type": "data_format2"
}
}
}
],
...
}
Example 1: Write one block of data for each received block of data¶

Fig. 5 Example 1: 6 images as input, 6 blocks of data produced
Consider the example toolchain on Fig. 5. We will implement a data-driven algorithm that will write one block of data on the output of the block for each image received on its inputs. This is the simplest case.
{
...
"groups": [
{
"inputs": {
"images": {
"type": "image/rgb"
},
"labels": {
"type": "label"
}
},
"outputs": {
"features": {
"type": "array/float"
}
}
}
],
...
}
class Algorithm:
def process(self, inputs, outputs):
# Ask the output to create a data object according to its data format
data = outputs['features'].createData()
# Compute something from inputs['images'].data and inputs['labels'].data
# and store the result in 'data'
...
# Write our data block on the output
outputs['features'].write(data)
return True
The structure of the data object is dependent of the data format assigned
to the output.
Example 2: Skip some blocks of data¶

Fig. 6 Example 2: 6 images as input, 4 blocks of data produced, 2 blocks of data skipped
Consider the example toolchain on Fig. 6. This time, our algorithm will use a criterion to decide if it can perform its computation on an image or not, and tell the platform that, for a particular data index, no data is available.
{
...
"groups": [
{
"inputs": {
"images": {
"type": "image/rgb"
},
"labels": {
"type": "label"
}
},
"outputs": {
"features": {
"type": "array/float"
}
}
}
],
...
}
class Algorithm:
def process(self, inputs, outputs):
# Use a criterion on the image to determine if we can perform our
# computation on it or not
if can_compute(inputs['images'].data):
# Ask the output to create a data object according to its data format
data = outputs['features'].createData()
# Compute something from inputs['images'].data and inputs['labels'].data
# and store the result in 'data'
...
# Write our data block on the output
outputs['features'].write(data)
else:
# Tell the platform that no data is available for this image
outputs['features'].write(None)
return True
def can_compute(self, image):
# Implementation of our criterion
...
return True # or False
Example 3: Write one block of data related to several received blocks of data¶

Fig. 7 Example 3: 6 images as input, 2 blocks of data produced
Consider the example toolchain on Fig. 7. This time, our algorithm will compute something using all the images with the same label (all the dogs, all the cats) and write only one block of data related to all those images.
The key here is the correct usage of the current end data index of the input list to specify the indexes of the blocks of data we write on the output. This ensure that the data will be synchronized everywhere in the toolchain: the platform can now tell, for each of our data block, which image and label it relates to (See section Inputs synchronization).
Additionally, since we can’t know in advance if the image currently processed is the last one with the current label, we need to memorize the current data index of the input list to correctly assign it later when we effectively write the data block on the output.
{
...
"groups": [
{
"inputs": {
"images": {
"type": "image/rgb"
},
"labels": {
"type": "label"
}
},
"outputs": {
"features": {
"type": "array/float"
}
}
}
],
...
}
class Algorithm:
def __init__(self):
self.data = None # Block of data updated each time we
# receive a new image
self.current_label = None # Label of the images currently processed
self.previous_data_index = None # Data index of the input list during the
# processing of the previous image
def process(self, inputs, outputs):
# Determine if we already processed some image(s)
if self.data is not None:
# Determine if the label has changed since the last image we processed
if inputs['labels'].data.name != self.current_label:
# Write the block of data on the output
outputs['features'].write(data, self.previous_data_index)
self.data = None
# Memorize the current data index of the input list
self.previous_data_index = inputs.current_end_data_index
# Create a new block of data if necessary
if self.data is None:
# Ask the output to create a data object according to its data format
self.data = outputs['features'].createData()
# Remember the label we are currently processing
self.current_label = inputs['labels'].data.name
# Compute something from inputs['images'].data and inputs['labels'].data
# and update the content of 'self.data'
...
# Determine if this was the last block of data or not
if not(inputs.hasMoreData()):
# Write the block of data on the output
outputs['features'].write(self.data, inputs.current_end_data_index)
return True