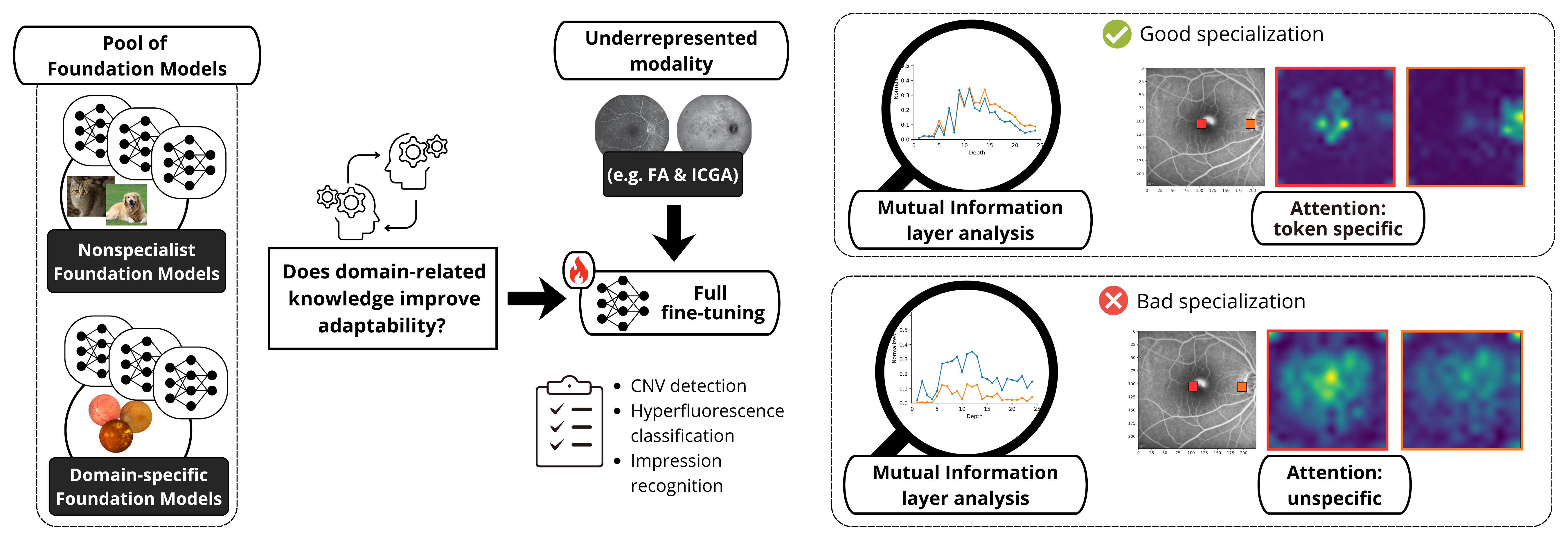
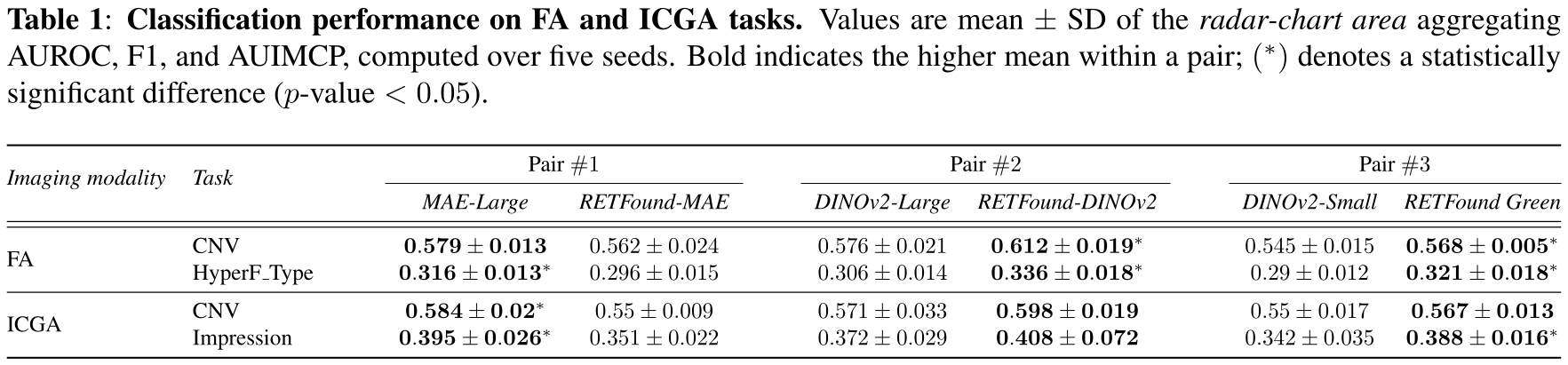
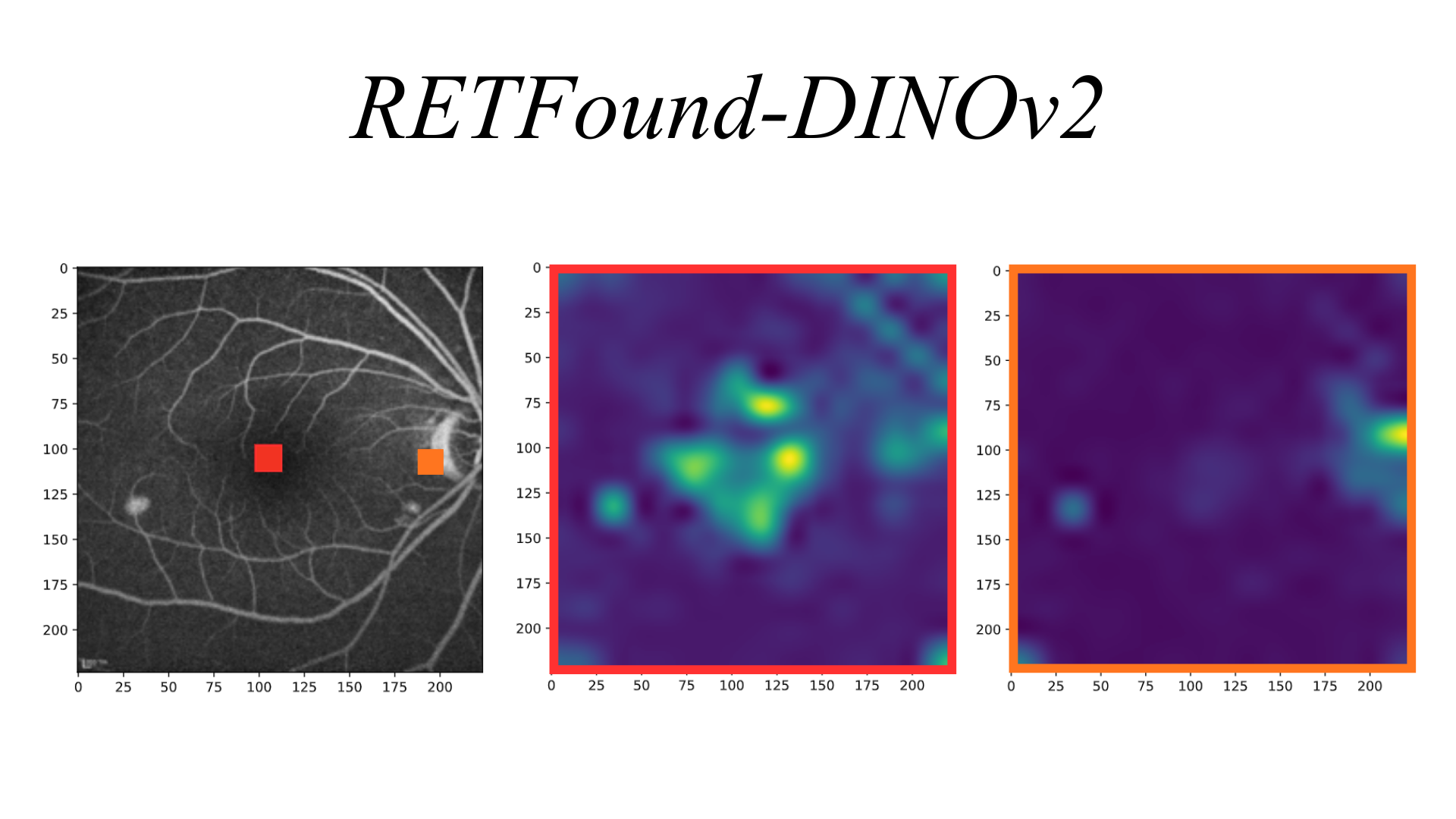
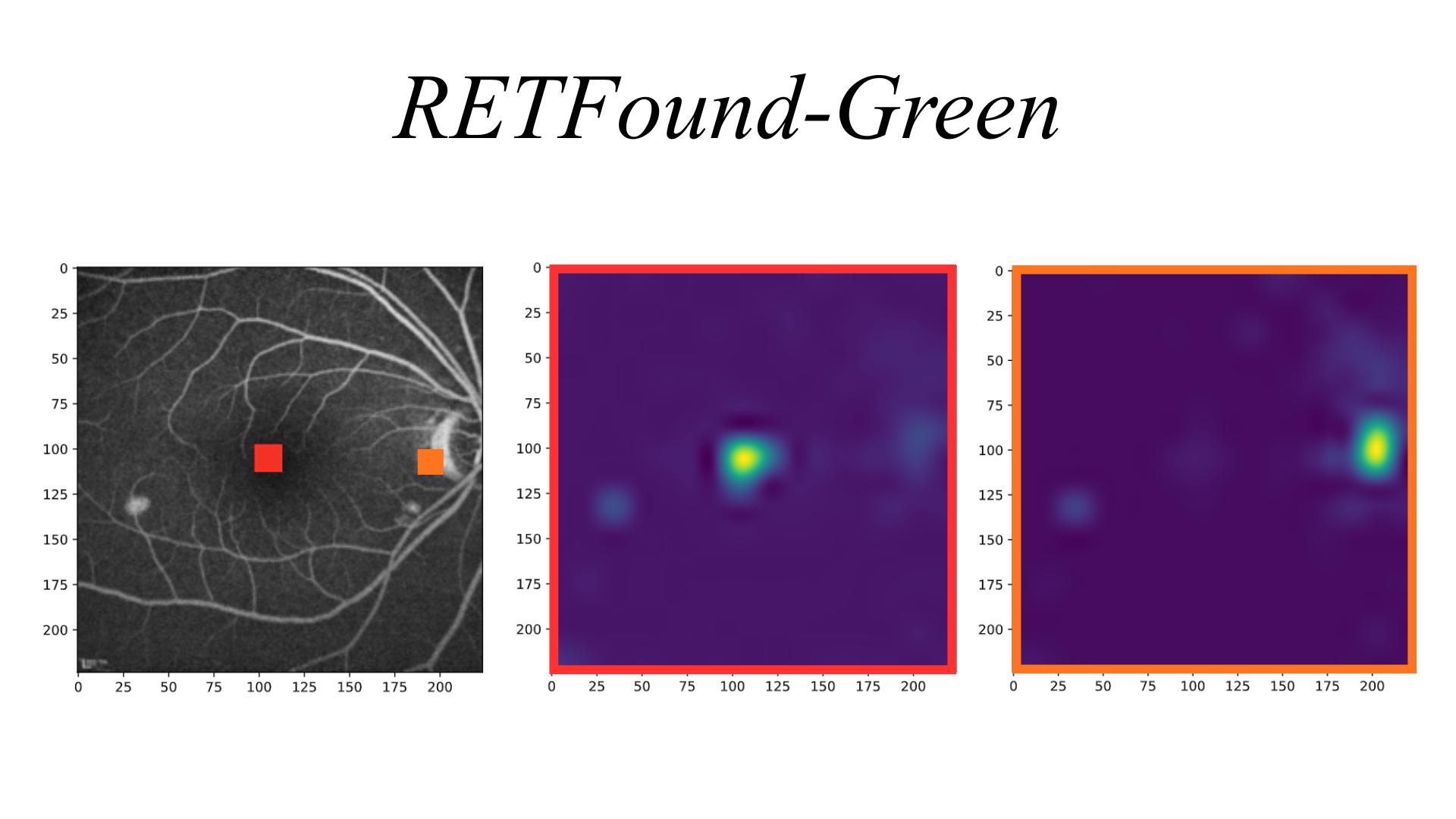
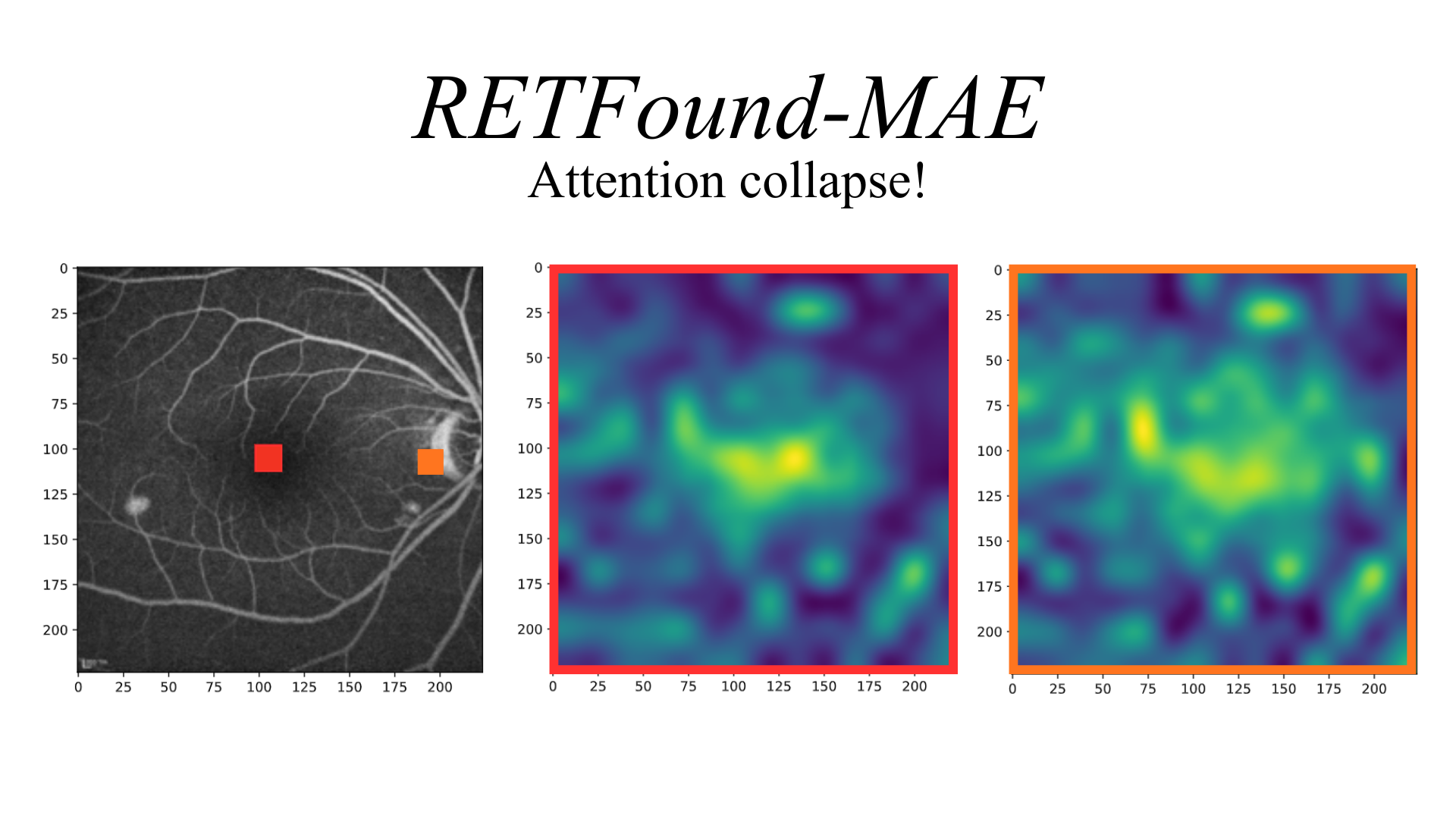
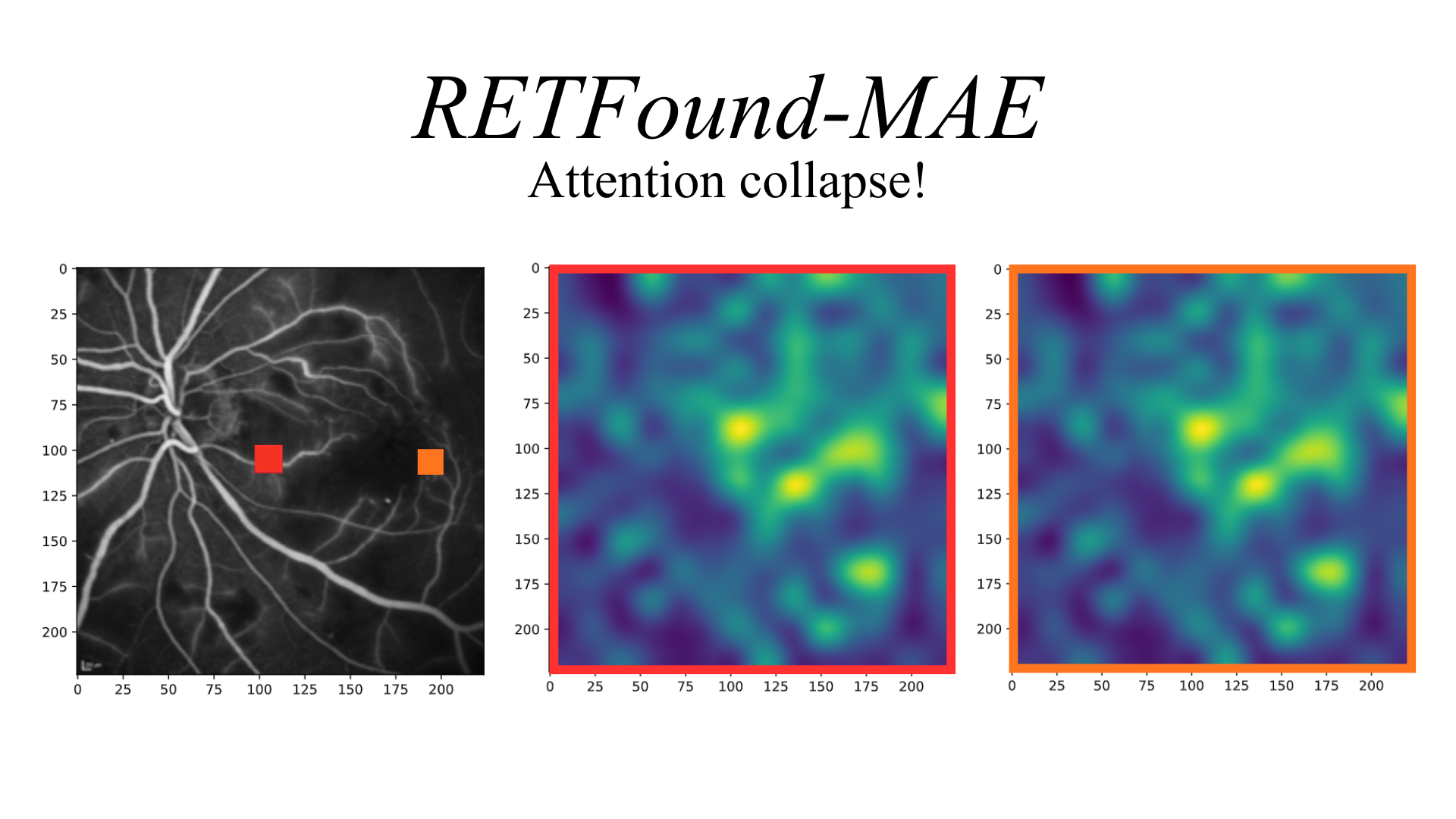
The role of specialization in cross-modality transfer. Retinal FMs with higher mutual information and context-aware attention maps achieve superior cross-modality adaptability (e.g., FA and ICGA tasks) than nonspecialist FMs.
Large publicly available datasets for specialized medical imaging are rare, limiting model development and motivating knowledge transfer from related, data-rich modalities. We explore this in ophthalmology by investigating whether retinal foundation models (FMs) pretrained on Color Fundus Photographs (CFP) transfer more effectively to other ophthalmic modalities, specifically Fluorescein Angiography (FA) and Indocyanine Green Angiography (ICGA), than nonspecialist FMs trained on natural images. In particular, we examine how the Self-Supervised Learning (SSL) strategy and model size influence this transfer. Using the public AngioReport dataset, six FMs were fine-tuned on three angiography tasks and thoroughly evaluated. Attention-based analyses, performed both quantitatively and qualitatively, further contextualized the results. Our experiments show that cross-modality transfer in retinal FMs is critically dependent on the SSL method applied during the pretraining phase: while DINOv2 and Token Reconstruction objectives preserve diverse representations that generalize well across modalities, MAE pretraining leads to overspecialization, a narrowing of representations that limits transferability to other retinal imaging domains.
The results of our study are presented here and show that effective cross-modality transfer in ophthalmic imaging depends critically on the self-supervised learning strategy used during pretraining.


@INPROCEEDINGS{11515636,
author={Pulvirenti, Roberto and Jimenez-del-Toro, Oscar and Tomasoni, Mattia and Hoogewoud, Florence and Anjos, André},
booktitle={2026 IEEE 23rd International Symposium on Biomedical Imaging (ISBI)},
title={When Specialization Helps (and Hurts): Cross-Modality Transfer in Ophthalmic Imaging with Foundation Models},
year={2026},
volume={},
number={},
pages={1-5},
doi={10.1109/ISBI61048.2026.11515636}
}