
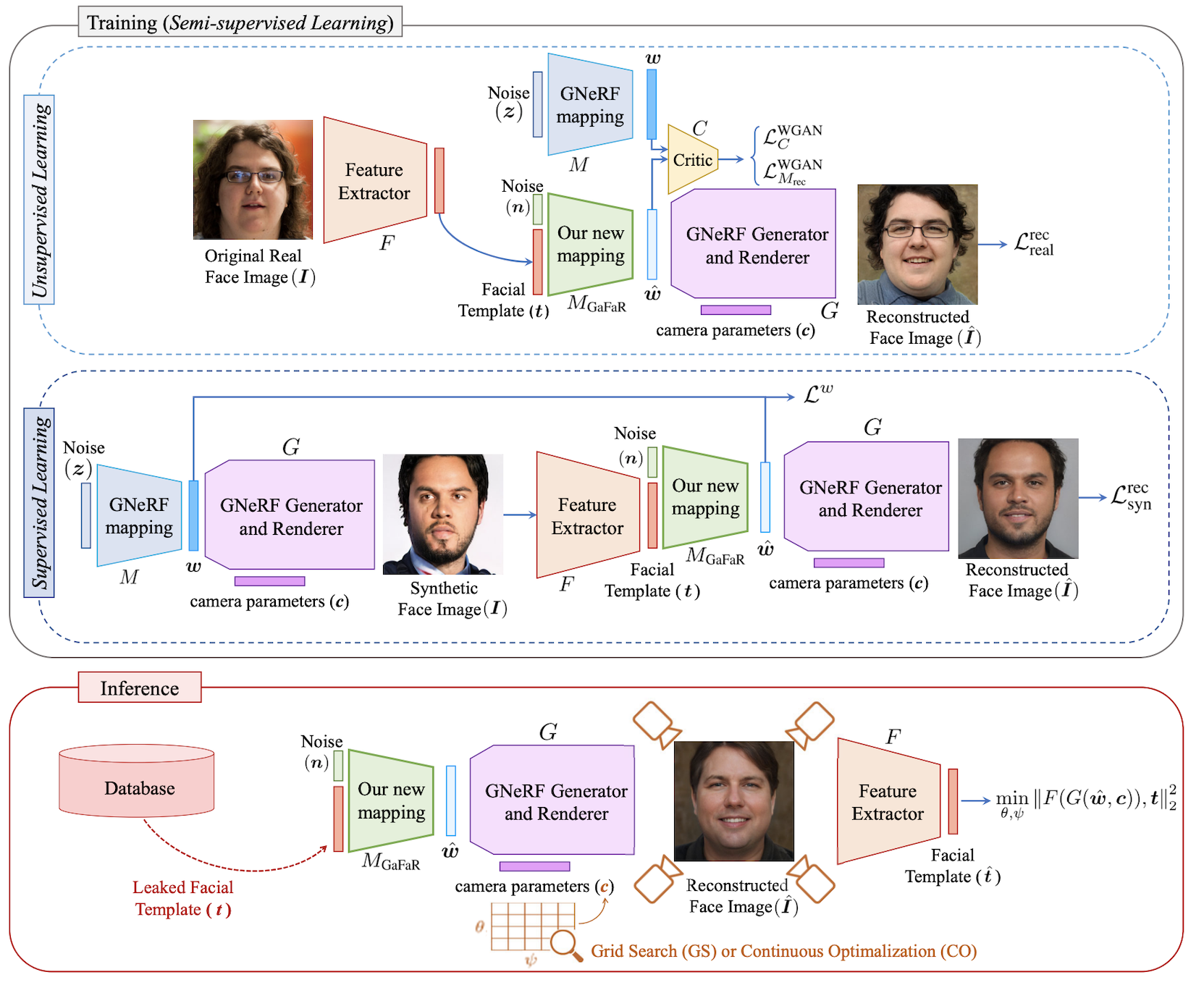
Block diagram of our proposed template inversion attack: During the training process, a semi-supervised approach is used to learn our mapping (illustrated as a green block) from the facial templates to the intermediate latent space of the GNeRF model. We use real training data and synthetic training data simultaneously for unsupervised and supervised learning in our method. In the inference stage, the leaked template is fed into our mapping network to find corresponding vector in the intermediate latent space of the GNeRF. Then, camera parameters along with generated latent code are given to the generator and renderer of GNeRF to generate a reconstructed face image. To enhance the attack, we propose an optimization (grid search or continuous optimization) on two of the camera parameters, to find the best pose, which minimizes the distance between the template of reconstructed face image and the leaked template.
For evaluation, we use the reconstructed face images and inject to the taget face recognition system. In our IEEE-TPAMI paper, we also perform practical presentation attack using the reconstructed face image. Th blockdiagram of our evaluation scenario is depicted in the following figure:
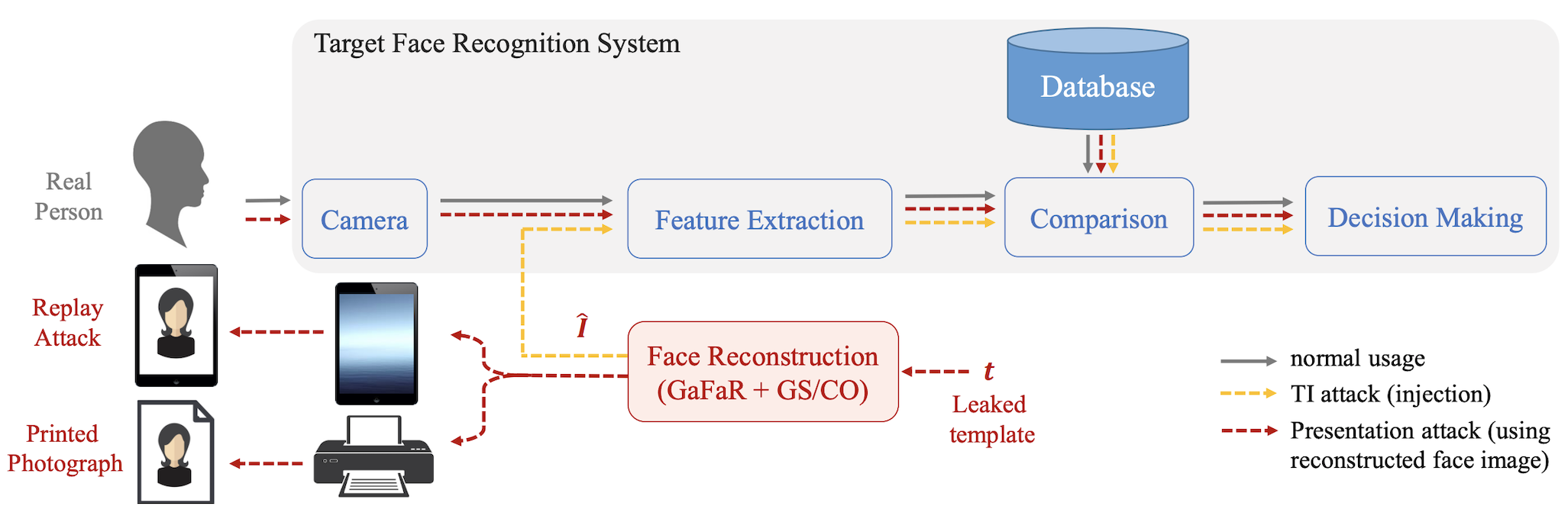
We performed practical presentation attack using the reconstructed face image. The following figure shows our evaluation setup for performing different types of presentation and capturing presentation using mobile devices (a) replay attack using Apple iPad Pro, and (b) presentation attack using printed photograph.

We considered three different mobile devices, including Apple iPhone 12, Xiaomi Redmi 9A, and Samsung Galaxy S9, as the camera of the target face recognition system and capture images from the presentations. The captured images from our presentation attacks are publicly available.
The source code of our experiments as well as captured images for our presentation attack evaluations are publicly availabble:
@article{tpami2023ti3d,
author = {Hatef Otroshi Shahreza and S{\'e}bastien Marcel},
title = {Comprehensive Vulnerability Evaluation of Face Recognition Systems to Template Inversion Attacks Via 3D Face Reconstruction},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year = {2023},
volume = {45},
number = {12},
pages = {14248-14265},
doi = {10.1109/TPAMI.2023.3312123}
}
@inproceedings{iccv2023ti3d,
author = {Hatef Otroshi Shahreza and S{\'e}bastien Marcel},
title = {Template Inversion Attack against Face Recognition Systems using 3D Face Reconstruction},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages = {19662--19672},
month = {October},
year = {2023}
}
