Vanilla Biometrics: Introduction to biometric recognition in practice¶
To run biometric experiments, we provide a generic CLI command called bob bio pipelines.
Such CLI command is an entry-point to several pipelines implemented under bob.pipelines.
This tutorial will focus on the pipeline called vanilla-biometrics.
In our very first example, we’ve shown how to compare two samples using the bob bio compare-samples command, where the “biometric” algorithm is set with the argument -p.
The -p points to a so-called VanillaBiometricsPipeline.
Running a biometric experiment with Vanilla Biometrics¶
A set of commands are available to run Vanilla Biometrics experiments from the shell. Those are in the form of:
$ bob bio pipelines vanilla-biometrics [OPTIONS] -p <pipeline>
With the -p option being mandatory as it specifies the configuration of the pipeline. The other options can be listed with:
$ bob bio pipelines vanilla-biometrics --help
Building your own Vanilla Biometrics pipeline¶
The Vanilla Biometrics represents the simplest biometrics pipeline possible and for this reason, is the backbone for any biometric test in this library. It’s composed of:
Transformers: Instances of
sklearn.base.BaseEstimatorandsklearn.base.TransformerMixin. A Transformer can be trained if needed and applies one or several transformations on an input sample. It must implement atransform()and afit()method. Multiple transformers can be chained together, each working on the output of the previous one.A Biometric Algorithm: Instance of
BioAlgorithmthat implements the methodsenroll()andscore()to generate biometric experiment results.
Running the vanilla-biometric pipeline will retrieve samples from a dataset and generate score files.
It does not encompass the analysis of those scores (Error rates, ROC, DET). This can be done with other utilities of the bob.bio packages.
Transformer¶
Following the structure of pipelines of scikit-learn, a Transformer is a class that must implement a transform() and a fit() method.
This class represents a simple operation that can be applied to data, like preprocessing of a sample or extraction of a feature vector from data.
A Transformer must implement the following methods:
-
Transformer.transform(data)¶ This method takes data as input and returns the corresponding transformed data. It is used for preprocessing and extraction.
-
Transformer.fit(data, label)¶ A
Transformercan be trained with itsfit()method. For example, for Linear Discriminant Analysis (LDA), the algorithm must first be trained on data.This method returns the trained instance of the
Transformerclass, or the instance of the class itself (self) if theTransformeris not trainable.
Note
Not all Transformers need to be trained (via a fit() method).
For example, a preprocessing step that crops an image to a certain size does not require training. In this case, the fit() method returns self.
Below is an example implementing a very simple Transformer applying a custom function on each sample given as input.
from sklearn.base import TransformerMixin, BaseEstimator
class CustomTransformer(TransformerMixin, BaseEstimator):
def transform(self, X):
transformed_X = my_function(X)
return transformed_X
def fit(self, X, y=None):
return self
Biometric Algorithm¶
A biometric algorithm represents the enrollment and scoring phase of a biometric experiment.
A biometric algorithm is a class implementing the method enroll() that allows to save the identity representation of a subject, and score() that computes the score of a subject’s sample against a previously enrolled model.
A common example of a biometric algorithm class would compute the mean vector of the features of each enrolled subject, and the scoring would be done by measuring the distance between the unknown identity vector and the enrolled mean vector.
-
BiometricAlgorithm.enroll(reference_sample)¶ The
enroll()method takes extracted features (data that went through transformers) of the reference samples as input. It should save (on memory or disk) a representation of the identity of each subject for later comparison with thescore()method.
-
BiometricAlgorithm.score(model, probe_sample)¶ The
score()method also takes extracted features (data that went through transformers) as input but coming from the probe samples. It should compare the probe sample to the model and output a similarity score.
Here is a simple example of a custom BioAlgorithm implementation that computes a model with the mean of multiple reference samples, and measures the inverse of the distance as a similarity score.
from bob.bio.base.pipelines.vanilla_biometrics.abstract_classes import BioAlgorithm
class CustomDistance(BioAlgorithm):
def enroll(self, enroll_features):
model = numpy.mean(enroll_features, axis=0)
return model
def score(self, model, probe):
distance = 1/numpy.linalg.norm(model-probe)
return distance
Constructing the pipeline¶
As stated before, a pipeline is a series of Transformers and a BiometricAlgorithm chained together.
In Vanilla biometrics, 3 sub-pipelines are defined: a training pipeline, an enrollment pipeline, and a scoring pipeline.
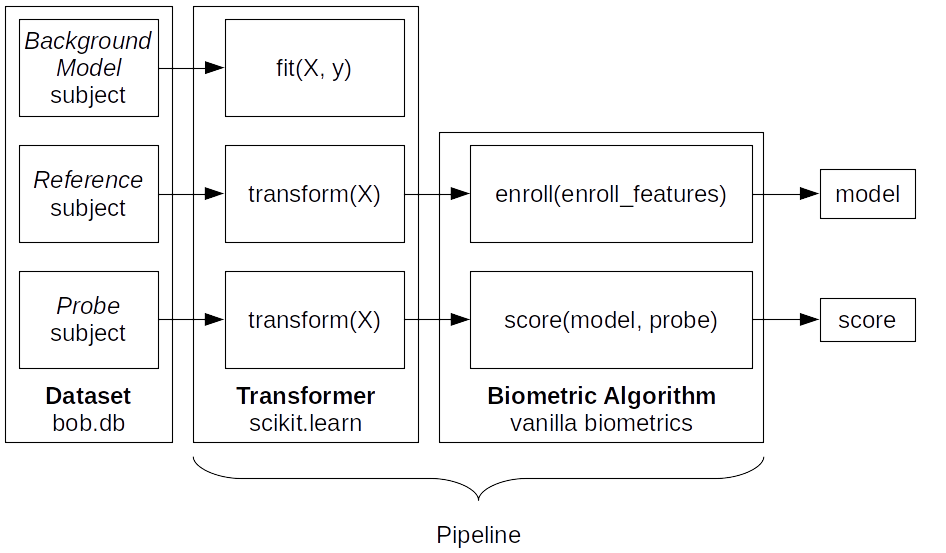
Fig. 8 Example of a pipeline showing the sub-pipelines. The data of references is used for enrollment and the data of probes is used for scoring.
Each subject’s data goes through the Transformer (or series of Transformers) before being given to enroll() or score().¶
Here is the creation of the pipeline combining the Transformer and the BioAlgorithm that we implemented earlier:
from sklearn.pipeline import make_pipeline
from bob.pipelines import wrap
from bob.bio.base.pipelines.vanilla_biometrics import VanillaBiometricsPipeline
# Instantiate the Transformer(s)
my_transformer = CustomTransformer()
# Chain the Transformers together
transformer = make_pipeline(
wrap(["sample"], my_transformer),
# Add more transformers here if needed
)
# Instantiate the BioAlgorithm
bio_algorithm = CustomDistance()
# Assemble the Vanilla Biometric pipeline and execute
pipeline = VanillaBiometricsPipeline(transformer, bio_algorithm)
# The `pipeline` variable will be used by the vanilla-pipeline script
Then to execute this pipeline the following command can be executed, using the AT&T face dataset:
$ bob bio pipelines vanilla-biometrics --pipeline my_pipeline.py --database atnt --output results
This will create a results folder with a scores-dev file in it containing the similarity score for each probe against every model.
Minimal example of the vanilla-biometrics pipeline¶
Find below a complete file containing a Transformer, a Biometric Algorithm, and the construction of the pipeline:
Complete pipeline construction
import numpy
## Implementation of a Transformer
from sklearn.base import TransformerMixin, BaseEstimator
class CustomTransformer(TransformerMixin, BaseEstimator):
def transform(self, X):
transformed_X = X
return transformed_X
def fit(self, X, y=None):
return self
## Implementation of the BioAlgorithm
from bob.bio.base.pipelines.vanilla_biometrics.abstract_classes import BioAlgorithm
class CustomDistance(BioAlgorithm):
def enroll(self, enroll_features):
model = numpy.mean(enroll_features, axis=0)
return model
def score(self, model, probe):
distance = 1/numpy.linalg.norm(model-probe)
return distance
## Creation of the pipeline
from sklearn.pipeline import make_pipeline
from bob.pipelines import wrap
from bob.bio.base.pipelines.vanilla_biometrics import VanillaBiometricsPipeline
# Instantiate the Transformers
my_transformer = CustomTransformer()
# Chain the Transformers together
transformer = make_pipeline(
wrap(["sample"], my_transformer),
# Add more transformers here if needed
)
# Instantiate the BioAlgorithm
bio_algorithm = CustomDistance()
# Assemble the Vanilla Biometric pipeline and execute
pipeline = VanillaBiometricsPipeline(transformer, bio_algorithm)
# Prevent the need to implement a `score_multiple_biometric_references` method
database.allow_scoring_with_all_biometric_references = False
# `pipeline` will be used by the `bob bio pipelines` command
To run the simple example above, save that code in a file my_pipeline.py and enter this command in a terminal:
$ bob bio pipelines vanilla-biometrics -d atnt -p my_pipeline.py -o results
This will create a file results/scores-dev containing the distance between each pair of probe and reference sample.
Structure of a pipeline package¶
In a serious scenario with more complex and longer implementations, you should separate the definition of Transformers and BioAlgorithm in different files that can be swapped more easily.
bob.bio packages also provide commonly used Transformers and BioAlgorithm that you can import. You can list them with the following command:
$ resources.py