
Idiap Research Institute
Centre du Parc
Rue Marconi 19
PO Box 592
CH - 1920 Martigny
Switzerland
T +41 27 721 77 11
F +41 27 721 77 12
(Archives 2012) VLBR-SPEECH CODING demonstration page, 2012
RECOD 2011 work showed feasibility of very low bit rate (VLBR) speech coding using convergence of automatic speech recognition and text-to-speech technologies. The encoder transcribed spoken words into text, the letters (graphemes) were transmitted around 100 bps through TCP/IP communication channel, and the decoder synthesized the text back to speech. The main problem identified was dependency on spoken language. In addition, the system was based on word recognition, and so all speech recognition errors were propagated to the coding system, and it could significantly hurt the performance if the system.
First, we investigated the impact of vocoders on the speech coding system. The following content (block highlighted in gray) shows examples of tested and evaluated vocoders.
VLBR-SPEECH CODING demonstration page
Vocoder comparision. STRAIGHT, SPTK, LPC use 24 analysis order
| Vocoder Type | Fully vocoded [PESQ] (MOS-LQO) |
Synthesis from HMMs [PESQ] (MOS-LQO) |
Fully vocoded [PESQ] (MOS-LQO) |
Synthesis from HMMs [PESQ] (MOS-LQO) |
|---|---|---|---|---|
| Original | ||||
| STRAIGHT (spec) | ||||
| STRAIGHT (cep) | ||||
| STRAIGHT (cep, no apperiodicity) | ||||
| LPC10 - 8kHz, 2.4kbps | ||||
| LPC10 - 8kHz, ~ 2.1kbps, white noise exc. | ||||
| LPC from Phil, continuous pitch | ||||
| LPC from Phil, Liljencrants-Fant glottal model | ||||
| LPC from SPTK, excit. from pitch seq. | ||||
| HNM | ||||
| HNM EMIME | ||||
| SPTK (cep) |
Following demonstration of various VLBR speech coding algorithms is obsolete.
| Type | Description | Example |
|---|---|---|
| Original | WSJ random male sample (IMPORTS OF MANUFACTURED GOODS SOARED SIXTY TWO PERCENT PERIOD) | |
| HTS full context synthesis (no ASR errors) | HTS synthesis from full-context labels, STRAIGHT vocoder, original En_UK Emime models used. | |
| HMM-TTS synthesis w/o cotext (no ASR errors) | HMMs trained from MFCC 39-order cepstras plus delta and double delta (i.e. 120 VECSIZE), single GMMs triphones trained. The example is concatenation of means and variances of corresponding labels, and synthesized using mlsadf filter (from SPTK). | |
| HNM synthesis | HNM coding, original HMMs used (from Petr's work). |
We continued with technology towards language independent system. Supposing that spoken phonemes (phones) are necessary for multilingual system, we used in the encoder phoneme-based speech recognition. This allows also to avoid word recognition errors presented in 2011 prototype. The next table presents examples of the HMM coding system working on phoneme level. The encoder sends:
- indices of phonemes (around 50 bps)
- durations and pitch of phonemes (another 50 bps) - it is not necessary to transmitt it, it might be synthesized from HMM models.
There are two options with HMM modeling for VLBR speech coding:
- Use the common training setup for ASR models and TTS models, with the same training material (incl. training dictionaries). The advantage is that encoded phoneme labels (from ASR) could be directly used for construction of TTS labels, as the phoneme set is the same. For this case, we used WSJ setup, three-state, cross-word triphone models, trained from 120 dimensional MFCCs (39 cepstral plus energy coef. including delta and delta-delta features) for TTS, and 39 dimensional MFCCs for ASR. Encoder sends the phoneme labels, and the decoder constructs triphone contextual labels. According to the duration of the labels, the Gaussians from the TTS AMs are grouped (we get pdf from a sequence of HMMs), and the speech parameters (static cepstra) are estimated using the mlpg tool. Finally, resynthesis from the cepstra is used for speech generation. An example of coded speech with STRAIGHT vocoder is .
- Use different training setups for ASR models and TTS models, using different training materials incl. different dictionaries. The disadvantage of the approach is that we need to map encoded and decoded labels. For this case, we used WSJ setup described below for phoneme recognition, and high quality HMM-TTS 48kHz voice, trained from RJS Blizzard challenge 2010 data, and adapted to Roger voice from the same challenge. As ASR encoding uses 40 phonemes, and TTS voice uses 60 phonemes (from unilex-rpx dictionary), the mapping is performed as follows:
# WSJ to unilex map unimap = { 'M':'m', 'N':'n', 'NG':'ng', 'P':'p', 'B':'b', 'T':'t', 'D':'d', 'K':'k', 'G':'g', 'F':'f', 'V':'v', 'TH':'th', 'DH':'dh', 'S':'s', 'Z':'z', 'SH':'sh', 'ZH':'zh', 'HH':'h', 'R':'r', 'Y':'y', 'L':'l', 'W':'w', 'CH':'ch', 'JH':'jh', 'IY':'iy', 'UW':'uw', 'IH':'ihr', 'UH':'uh', 'EH':'eh', 'ER':'er', 'AH':'ah', 'AO':'ao', 'AE':'ae', 'AA':'aa', 'EY':'ei', 'OW':'ow', 'OY':'oi', 'AW':'au', 'AY':'ai' }Even though the mapping discards 1/3 of TTS phonemes, plus the sentence context is not used at all, the quality of coded speech outperforms the quality of previous common training system. The examples are shown in the following table:
| Language | Systems | Examples: | VLBR-speech coding |
|---|---|---|---|
| English | Original | ||
| HMM coding with STRAIGHT | |||
| => phonemes only | (50 bps) | ||
| => phonemes plus durations | (70-80 bps) | ||
| => full stream, encoding tempo pitch | (100 bps) | ||
| => full stream, encoding cont. pitch | (100 bps) | ||
| => full stream, encoding cont. pitch, added ph in syl position | (100 bps) | ||
| => phonemes and words, discarding dur and f0 | (100 bps) |
Architecture of the experimental system:
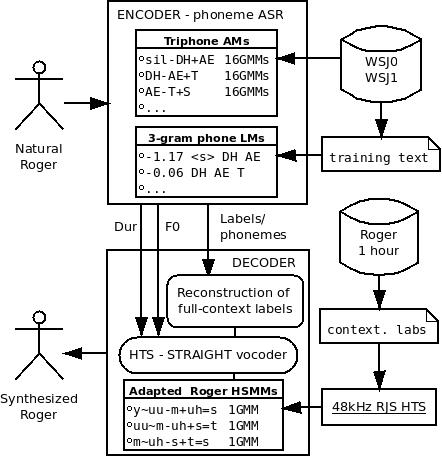
For phoneme recognition system we used WSJ setup. We developed HMM/GMM systems using WSJ0 and WSJ1 continuous speech recognition corpuses. All systems used three-state, cross-word triphone models, trained from tandem features from 3-layer MLP phone posteriors. Training was performed with the HTS variant of the HTK toolkit on the si_tr_s_284 set of 37,514 utterances. The language model was trained from forced mono-phone alignment utterances of the training set, using Witten-Bell discounting for N-grams of order 3. The performance on the testing set si_et_20 was:
====================== HTK Results Analysis ======================= Date: Thu Oct 4 10:54:29 2012 Ref : ../test-mfcc-si_et_20/align-mono.mlf Rec : decode.mlf ------------------------ Overall Results -------------------------- SENT: %Correct=0.30 [H=1, S=332, N=333] WORD: %Corr=86.80, Acc=83.43 [H=20341, D=885, S=2208, I=789, N=23434] ===================================================================