[m]odeling [a]nnotated [m]edia
Research team
- Florent Monay, IDIAP Research Institute, Switzerland
- Daniel Gatica-Perez, IDIAP Research Institute, Switzerland
Project goals
Using keywords to search for images and multimedia data is very intuitive, but requires text to be attached to the images first. Image search engines (google images, yahoo image search) rely for instance on the text surrounding an image, or on the corresponding image filename to match a text-based query with an image.
The mam project takes another direction, attempting to analyze the image content itself jointly with its description (see Fig. 1). We propose a probabilistic model where the two modalities are linked through a latent aspect variable. Three possibilities to learn the model have been investigated in [1] and [2].
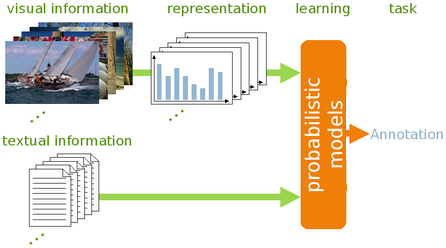
Figure 1 - click to enlarge
Probabilistic annotation
Given a model learned on a set of annotated images, a probability distribution over all the words that have been encountered can be estimated for any unseen image. We rely on an image representation that combines color information (HS) and invariant local descriptors (SIFT) to capture the image content. This image representation allows to estimate a probabilistic annotation (see Fig. 2 and Fig. 3) that can serve for image retrieval.

Figure 2 - click to enlarge

Figure 3 - click to enlarge
Demo
Try out the online image retrieval demo. This demo allows you to select between HS and SIFT features, or the combination of both. 1761 images can be searched with 144 keywords, based on their respective probability distribution.
Related publications
- F. Monay, Learning the structure of image collections with latent aspect models, PhD Thesis, 2007.
- F. Monay and D. Gatica-Perez, Modeling Semantic Aspects for Cross-Media Image Retrieval, IEEE Trans. on Pattern Analysis and Machine Intelligence, accepted for publication, Dec. 2006.
- F. Monay and D. Gatica-Perez, PLSA-based Image Auto-Annotation: Constraining the Latent Space, in Proc. ACM Int. Conf. on Multimedia (ACM MM), New York, Oct. 2004.
- F. Monay and D. Gatica-Perez, On Image Auto-Annotation with Latent Space Models, in Proc. ACM Int. Conf. on Multimedia (ACM MM), Berkeley, Nov. 2003.
Related project
CARTER: Classification of visual scenes using Affine invariant Regions and TExt Retrieval methods.
Acknowledgements
This research has been funded by the Swiss National Science Foundation (SNSF) through the MULTImodal Interaction and MULTImedia Data Mining (MULTI) project and the National Center of Competence in Research on Interactive Multimodal Information Management (IM2)